基于扩散模型的机器人操作学习
研究背景与扩散模型基础
机器人操作技术方法的演变
传统的机器人系统围绕着模块层级结构构建,包括感知、规划和控制,每个模块主要由数学模型和基于规则的策略驱动。这些方法为结构化环境提供了可靠且可解释的解决方案,但在应对不确定性、适应性和高维状态空间时遇到了困难[1],它们对精确建模和大量人工设计规则的依赖,使得它们在非结构化或动态环境中的效果欠佳。
最近,深度学习的迅速发展提升了机器人技术中的感知、控制和决策能力。在大规模数据集上预训练的视觉模型,如ResNet [2]、CLIP [3]等,已被广泛用于为下游机器人任务提取视觉表征。深度强化学习使机器人能够在高维空间中学习复杂任务,文献[4]便是例证。行为克隆借助大规模数据集取得了进展,通过数据集聚合等技术[5]缓解了其部分局限性。此外,视觉-语言-动作(VLA)模型[6]引入了多模态学习能力,使机器人能够利用文本和视觉输入来执行任务。尽管取得了这些进展,但大多数基于学习的方法在处理多模态分布时仍面临困难,有些方法还面临训练难度大、精度不足等挑战。最近,扩散策略[7]的兴起旨在通过将扩散模型纳入视觉运动策略学习来解决这些问题。
扩散模型
在讨论扩散模型在机器人领域的应用之前,理解扩散过程的基本概念至关重要。具体而言,扩散模型在图像和视频生成任务中取得了显著成功,其主要形式包括去噪扩散概率模型(DDPM)[8]。接下来,我们利用DDPM来阐明扩散过程的核心。
具体来说,去噪扩散概率模型(DDPM)代表一类生成模型,这类模型通过迭代去噪过程来学习生成数据。这类模型的工作方式是,在正向过程中用高斯噪声逐渐破坏训练数据,然后在反向过程中学习逆转这种破坏,以生成新样本。从技术上讲,正向过程被定义为一个固定的马尔可夫链,它根据预定义的方差调度$\left{\beta_{\mathrm{t}}\right}{\mathrm{t}=1}^{\mathrm{T}}$在$T$个时间步内逐渐向数据中添加高斯噪声。给定一个数据点$x_0$,在时间步$t$处被噪声破坏的样本$x_t$的分布为:
\(q\left(\boldsymbol{x}_{t} \mid \boldsymbol{x}_{t-1}\right)=\mathcal{N}\left(\boldsymbol{x}_{t} ; \sqrt{1-\beta_{t}} \boldsymbol{x}_{t-1}, \beta_{t} \boldsymbol{I}\right)\)
这一过程通过重参数化技巧实现了任意时间步的高效闭式采样:
\(\alpha_{t}=\prod_{i=1}^{t}\left(1-\beta_{i}\right) \epsilon \sim \mathcal{N}(0, I)\)
生成过程通过参数为的学习型马尔可夫链实现反向扩散:从高斯噪声$x{T} \sim {\mathcal{N}}(0, I)$出发,模型通过以下方式迭代去噪:
\(p_{\theta}\left(x_{t-1} \mid x_{t}\right)=\mathcal{N}\left(x_{t-1} ; \mu_{\theta}\left(x_{t}, t\right), \Sigma_{\theta}\left(x_{t}, t\right)\right)\)
这里${\mu}{\theta}$和${\Sigma}{\theta}$ 是学习得到的神经网络,用于预测反向分布的均值与协方差。DDPMs扩散概率模型通过最小化负对数似然的变分下界进行训练。关键性简化[8]采用噪声预测网络${\varepsilon}{\theta}$来预测前向过程中添加的噪声${\varepsilon}$:
\(\mathcal{L}=\mathbb{E}_{t, x_{0}, \epsilon}\left[\left\|\epsilon-\epsilon_{\theta}\left(x_{t}, t\right)\right\|^{2}\right]\)
其中${t}$从{ $1,2…T$ }均匀采样。当${\varepsilon}{\theta}$训练完成后,我们可以首先生成高斯噪声样本$x_T$,然后通过$x_{t-1} \sim p_{\theta}\left(x_{t-1} \mid x_{t}\right)$逐步去噪直到时间步达到$1$,从而生成新数据$x_0$。扩散过程的内在特性使其特别适合需要序列决策的机器人应用——相比其他生成方法,扩散模型既能捕捉复杂的多模态分布,又能保持训练过程的稳定性。
扩散策略(Diffusion as Policy)
扩散策略概述
受图像和视频生成领域中扩散模型进展的启发,Chi等人[7]通过将扩散过程应用于动作轨迹生成,引入了扩散策略的概念,这标志着该方法在机器人领域的首次应用。
从演示中学习策略通常被表述为一个回归问题,即将环境观测映射到相应的动作。然而,传统方法可能难以应对机器人应用中所需的多模态特性和精确动作控制。扩散模型凭借其强大的生成能力和强大的分布表达能力,为机器人策略学习提供了一种有前景的替代方案。
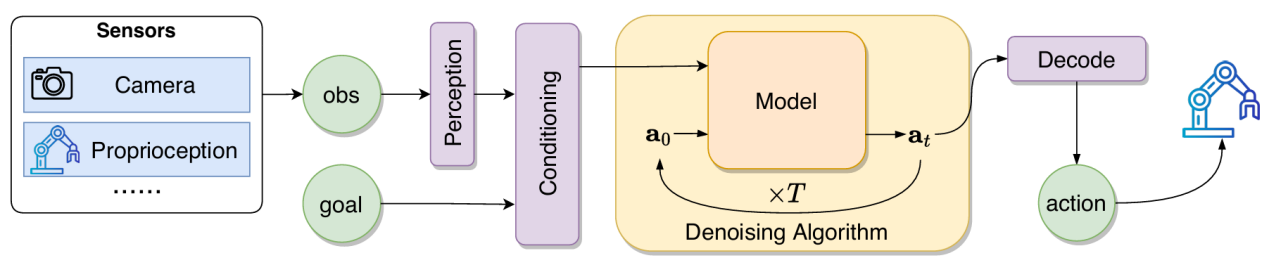 图1: 机器人中扩散策略方法的整体结构
图1: 机器人中扩散策略方法的整体结构
如图1所示,设计了一个通用的扩散策略框架,该框架将时间步的状态观测值$O_t$作为输入,并生成动作轨迹片段$\alpha_t$ = ($a_t, a_{t+1}, …,a_{t+H}$),其中$H$表示预测范围。生成过程遵循相同的迭代去噪过程,但有两个关键修改:(1)去噪目标在传统扩散模型中原先记为$x_t$,现被行动轨迹$\alpha_t$取代。(2)去噪过程以观测值$O_t$为条件,使策略能够根据当前状态相应地生成动作。
总之,扩散策略具有以下几个优点:
(1)对多模态分布建模能力。通过学习动作分布得分函数的梯度,扩散策略自然地适应多种有效的动作模式。随机初始化和迭代优化使策略能够探索不同的收敛域,并对多模态行为进行建模。
(2)精确动作控制。与传统的策略学习方法相比,扩散策略能够实现显著更精确和更细粒度的控制。这是通过一个迭代去噪过程实现的,该过程逐步地重新精细化控制信号,而固有的多模态建模增强了不确定性的表征。
(3)高维输出能力。扩散模型在生成高维输出方面展现出了卓越的可扩展性。在机器人领域中,这意味着策略可以联合预测一系列在执行过程中保持时间一致性的动作。
(4)训练稳定。与基于能量的策略不同,后者需要估计归一化常数,而扩散公式通过直接学习噪声到动作的映射,避开了这些问题,这使得训练动态更加稳定。
技术方法
在本节中,我们将简单从分层视角介绍基于扩散策略的机器人操作学习方法,以及不同方法的侧重点。其中主要从感知表示、算法设计两个角度分析:
感知表示层面
扩散策略在机器人任务中的有效性在很大程度上取决于机器人数据的表示和处理方式。本节将机器人感知方式主要分为三大类:图像感知、三维点云感知、触觉感知。
(1)RGB-D图像感知。
最基本的感知模块仅依赖RGB图像来捕捉环境信息,有些模块还会进一步利用深度信息。根据不同的方法,可以使用多个摄像头来更全面地了解环境,或者结合多个历史帧以确保更稳定的控制。此外值得注意的是,Point Policy [9]采用人类图像(或视频)的数据表示方式,这种表示方式为利用扩散模型解决机器人操作中的数据稀缺挑战提供了一种有前景的解决方案。
(2)3D点云感知。
3D表示通过明确的空间理解增强了扩散策略,使其能够在3D空间中更有效地推理物体关系和操作任务。作为该领域的一项开创性贡献,DP3 [10]通过稀疏点采样和高效的多层感知器(MLP)编码器开创了这种方法,以实现紧凑的3D表示,展现出优于2D策略的性能。
(3)触觉感知。
触觉传感器为机器人系统提供力和位置信息,实现更精细准确的操作。由于目前触觉传感器的多样性,感知技术也各不相同。两种主要类型的触觉传感器是基于图像的和基于力的。基于图像的触觉传感器输出RGB应变图图像,其中亮度表示深度,颜色表示切向应变。基于力的传感器通常采用嵌入式压力传感器和应变片直接测量接触力,有些将其转换为离散的小块。
算法设计层面
扩散策略在机器人操作中已展现出卓越的能力,然而,在算法设计层面可进一步提升其性能与适用性。本节简单列举在机器人领域推进扩散模型的几个关键方向,分别是:
(1)结合强化学习,通过奖励信号优化策略。
扩散模型显著改善了强化学习中复杂策略的参数化和优化。DPPO [11]将特定于扩散的去噪步骤整合到策略梯度优化中。这种结构化方法显著增强了训练的稳定性和效率,在复杂机器人操作任务的策略微调中尤为有效。
(2)开发加速采样或去噪策略,提高计算效率。
尽管扩散模型在生成复杂分布方面能力强大,但由于其本质上的迭代采样过程,在机器人实时应用中面临挑战,众多方法通过加速去噪技术来解决这一计算瓶颈。BESO [12]将分数模型学习与推理解耦,仅需3步去噪即可生成目标条件行为,而传统方法通常需要30步以上。
(3)设计改进的分类器引导技术,在满足特定约束的同时增强输出生成。
SkillDiffuser [13]将技能抽象与条件扩散规划相结合,使用无分类器的扩散引导,将轨迹采样与所需特征对齐,该方法显著增强了扩散模型生成满足机器人应用中特定约束或条件的输出的能力。
- [1]S. Haldar and L. Pinto, “Point policy: Unifying observations and actions with key points for robot manipulation,” arXiv preprint arXiv:2502.20391, 2025.
- [2]Y. Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,” arXiv preprint arXiv:2403.03954, 2024.
- [3]Z. Liang, Y. Mu, H. Ma, M. Tomizuka, M. Ding, and P. Luo, “Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16467–16476.
- [4]C. Chi et al., “Diffusion policy: Visuomotor policy learning via action diffusion,” The International Journal of Robotics Research, p. 02783649241273668, 2023.
- [5]A. Brohan et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” arXiv preprint arXiv:2307.15818, 2023.
- [6]M. Reuss, M. Li, X. Jia, and R. Lioutikov, “Goal-conditioned imitation learning using score-based diffusion policies,” arXiv preprint arXiv:2304.02532, 2023.
- [7]A. Radford et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning, 2021, pp. 8748–8763.
- [8]J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020.
- [9]D. Kalashnikov et al., “Scalable deep reinforcement learning for vision-based robotic manipulation,” in Conference on robot learning, 2018, pp. 651–673.
- [10]R. Alterovitz, S. Koenig, and M. Likhachev, “Robot planning in the real world: Research challenges and opportunities,” Ai Magazine, vol. 37, no. 2, pp. 76–84, 2016.
- [11]K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [12]S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics, 2011, pp. 627–635.
- [13]A. Z. Ren et al., “Diffusion Policy Policy Optimization,” in CoRL 2024 Workshop on Mastering Robot Manipulation in a World of Abundant Data.